vLLM throughput-latency sweep on NVIDIA A100
Benchmarking Llama-3.1-8B-Instruct from one concurrent request to 64, and reading the result against the A100’s memory roofline.

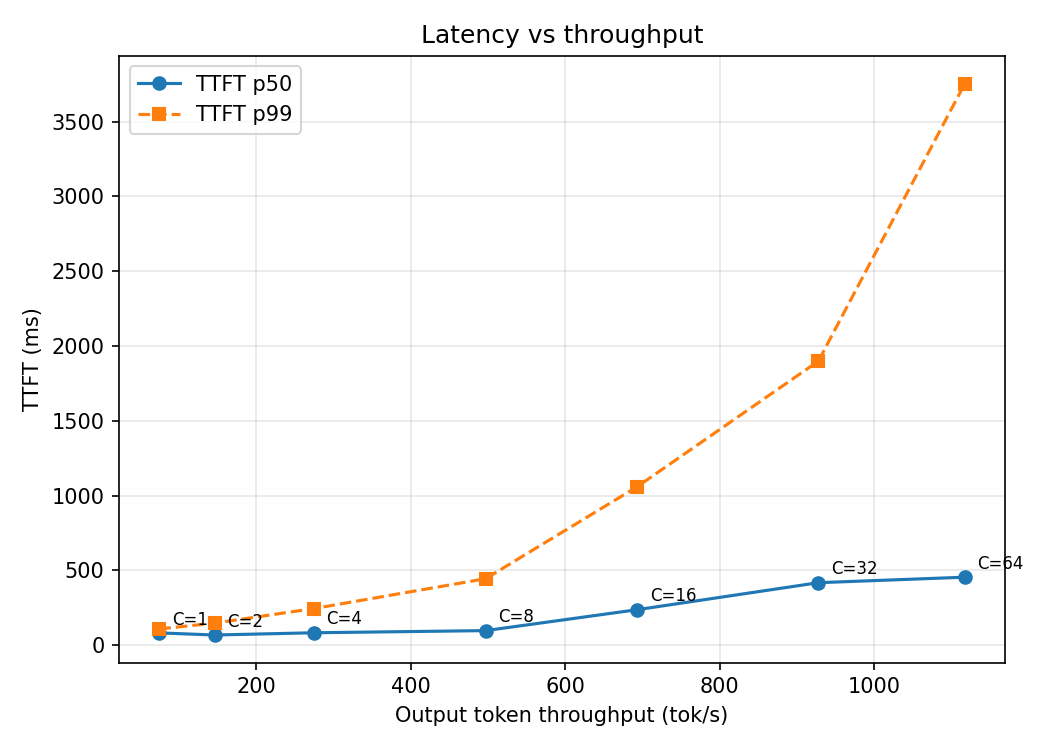
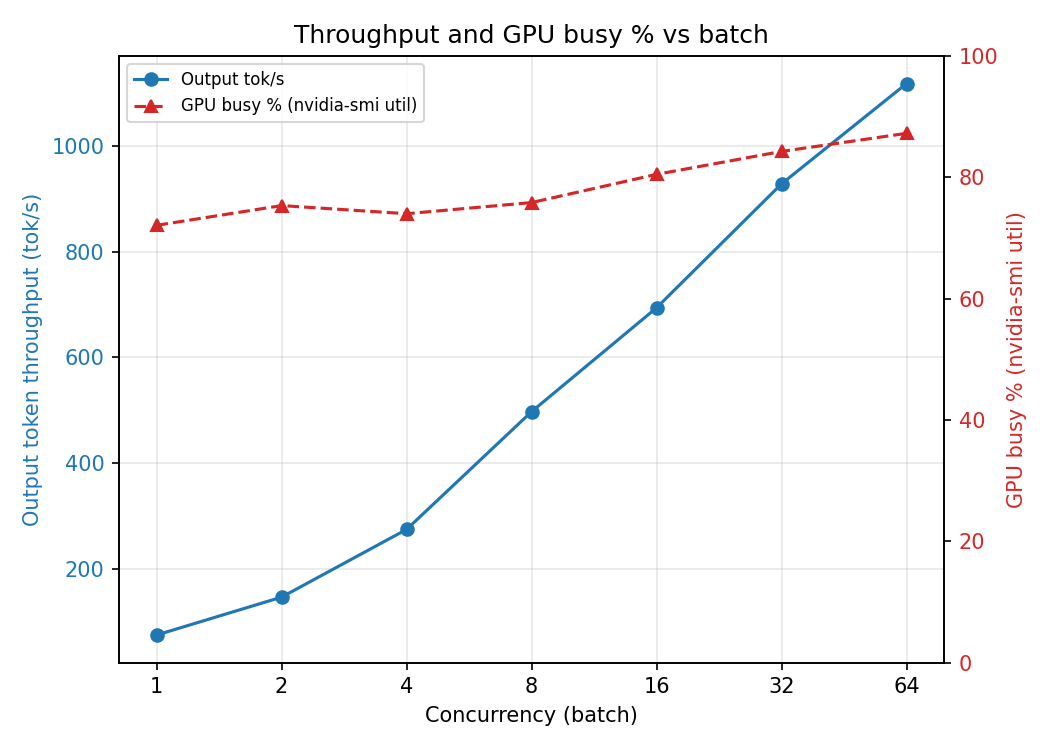
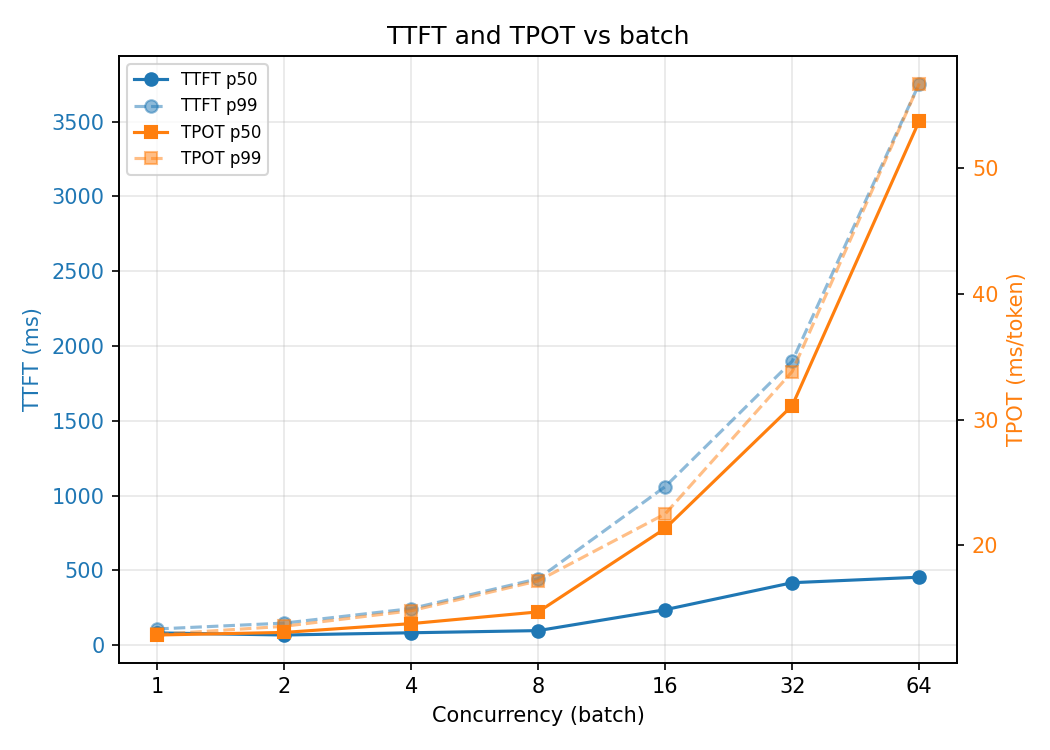
On a single NVIDIA A100 40GB, decode at one request per time runs at about 75 tokens/sec, roughly 77% of the GPU’s memory-bandwidth ceiling. Batching buys throughput almost for free up to a concurrency of 8, a 6.6x gain with almost no latency cost. Past that the curve bends: throughput keeps rising but per-token latency climbs and tail latency goes vertical. The knee sits at C=8, and that point, not peak throughput, is where you run a production system.
Setup
Everything run on a single node GPU, no tensor parallelism, with default vLLM scheduling. The instance on Lambda also has 30 vCPU’s, 1800 GB RAM, and a 6TB SSD.
GPU: NVIDIA A100 40GB (using Lambda)
Model:
meta-llama/Llama-3.1-8B-Instruct, BF16vLLM 0.23.0
vllm serve meta-llama/Llama-3.1-8B-Instruct
Method
We can perform a concurrency sweep by varying the number of requests from 1 to 64, doubling each step. This varies the request load to measure the impact on latency and throughput. Every request used a fixed 1024-token input and a fixed 128-token output, with --ignore-eos so the model always generates exactly 128 tokens. Fixed lengths keep the curve clean; variable lengths smear every point because each concurrency level ends up averaging over a different length distribution.
for C in 1 2 4 8 16 32 64; do
vllm bench serve --model meta-llama/Llama-3.1-8B-Instruct \
--dataset-name random --random-input-len 1024 --random-output-len 128 \
--ignore-eos --max-concurrency $C --num-prompts $((C*20)) \
--request-rate inf --metadata vllm=0.23.0 gpu=a100-40gb \
--save-result --result-filename sweep_c${C}.json
done