Pre-training an LLM base model (for under $20)

I was inspired by Andrej Karpathy’s Nanochat to train an LLM base model from scratch. I tried to keep the budget under $20 using an A100 NVIDIA on Lambda. I will make the weights from pre-training public.
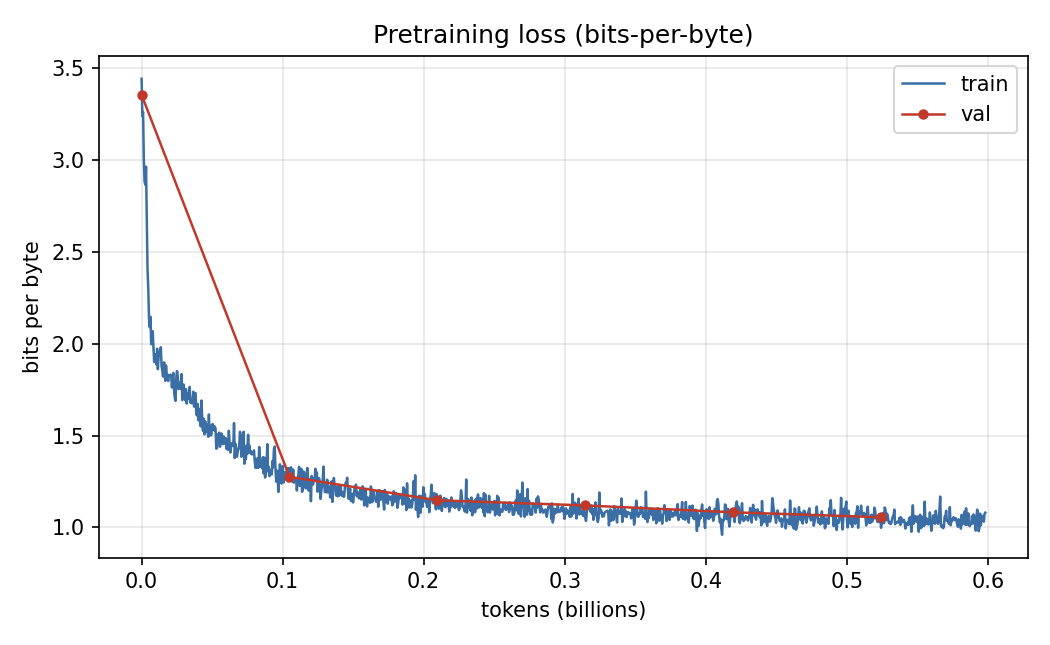
Base Model Training
The Transformer architecture has 12 layers, which is enough to run in about an hour on a single GPU instance.
To calculate the parameters, we need to calculate the embedding dimensionality by multiplying the number of layers by the aspect ratio. (GPT-2 and Karpathy use 64). d = 12 * 64, or 768. So we have 4 attention matrices of 768x768, one for Q,K,V and a projected matrix. 4 * d^2 = 2,359,296. The feed-forward network in the Transformer are 4x the dimensionality, and there is a fully connected layer 768x3072 and a projected layer 3072x768. So each layer has about 7 Million parameters. We also need embeddings for the input and output, and these are the 50,357 vocab times the dimensionality. 38 Million * 2. The total parameters are 162 Million.
Following the Chinchilla Scaling Law, we will need ~20 tokens per parameter for the training set, which is 3.2 Billion tokens. By selecting a batch size of 0.5M, this results in ~6k iterations during training.
Data: FineWeb-EDU
Using FineWeb-EDU which is the same as Nanochat. This is because the quality of the tokens is higher than FineWeb for smaller datasets.
My data step streams FineWeb-EDU from Hugging Face, tokenizes it with the gpt2 byte pair encoding (BPE) tokenizer, and writes flat uint16token files that the trainer memory-maps. We can always come back later and train a tokenizer for more efficiency
.
Architecture
Rotary position embeddings. RoPE encodes position by rotating queries and keys instead of adding a learned position vector. Two consequences downstream. There is no positional table to store or to run off the end of, and you can stretch context past the training length by changing the rotation base. And because position lives inside Q and K, the KV cache stores keys that are already rotated, so cached entries stay correct as you decode. RoPE and the KV cache fit together by design.
QK-norm. RMS-normalizing the queries and keys before attention bounds the size of the attention logits. At this scale it is mostly a training-stability win. The inference angle is quieter: bounded logits make low-precision attention less likely to overflow, which is exactly what you want when you are trying to run the score computation in fp8 or int8 to make decode cheaper.
Grouped-query attention. This one is pure inference economics, which is why I left it in as an option even though the small models do not need it. During decode the KV cache is what eats memory and bandwidth, and its size scales with the number of key/value heads. Dropping from one KV head per query head down to a small shared group shrinks the cache by that ratio with little quality loss. Decode is memory-bandwidth bound, so a smaller cache is close to a direct speedup at long context and large batch. Anyone who has read a decode roofline reaches for GQA.
Untied embeddings. nanochat does not share the input and output embedding matrices, so there are two vocab x dimmatrices instead of one. At a 50k-plus vocab that is real parameters and real weight-load bandwidth, and the output matrix is a large matmul in prefill and again every step of decode. Worth keeping in your head when you account for where the FLOPs and the bytes actually go.
Logit soft-cap. A tanh squashes the logits into a fixed range before the loss. Cheap, and it keeps the final big matmul’s outputs well-behaved for the same low-precision reasons as QK-norm.
bf16 activations, fp32 master weights. The model keeps fp32 weights for the optimizer but casts to bf16 inside the matmuls. Standard training setup, and also the cleanest version of the precision boundary you redraw later for inference, where you push activations and often weights down to fp8 or int8 and keep high precision only where the dynamic range demands it.
step 483/6184 | loss 3.5791 | bpb 1.1610 | lr 1.000 | 3508ms | 149,443 tok/s | MFU 29.8%
step 484/6184 | loss 3.5814 | bpb 1.0653 | lr 1.000 | 3509ms | 149,415 tok/s | MFU 29.8%
step 485/6184 | loss 3.5779 | bpb 1.0952 | lr 1.000 | 3512ms | 149,294 tok/s | MFU 29.8%
step 486/6184 | loss 3.5853 | bpb 1.0957 | lr 1.000 | 3519ms | 148,976 tok/s | MFU 29.7%
step 487/6184 | loss 3.5867 | bpb 1.0846 | lr 1.000 | 3510ms | 149,372 tok/s | MFU 29.8%
step 488/6184 | loss 3.5889 | bpb 1.0861 | lr 1.000 | 3509ms | 149,399 tok/s | MFU 29.8%
step 489/6184 | loss 3.5640 | bpb 1.1281 | lr 1.000 | 3509ms | 149,418 tok/s | MFU 29.8%
step 490/6184 | loss 3.5748 | bpb 1.1070 | lr 1.000 | 3522ms | 148,868 tok/s | MFU 29.7%
step 491/6184 | loss 3.5761 | bpb 1.1342 | lr 1.000 | 3512ms | 149,272 tok/s | MFU 29.8%
step 492/6184 | loss 3.5868 | bpb 1.0970 | lr 1.000 | 3509ms | 149,434 tok/s | MFU 29.8%
step 493/6184 | loss 3.5811 | bpb 1.0954 | lr 1.000 | 3508ms | 149,448 tok/s | MFU 29.8%
step 494/6184 | loss 3.6171 | bpb 1.1032 | lr 1.000 | 3510ms | 149,390 tok/s | MFU 29.8%
step 495/6184 | loss 3.5830 | bpb 1.1217 | lr 1.000 | 3505ms | 149,586 tok/s | MFU 29.9%
step 496/6184 | loss 3.6026 | bpb 1.1242 | lr 1.000 | 3510ms | 149,386 tok/s | MFU 29.8%
step 497/6184 | loss 3.5811 | bpb 1.0831 | lr 1.000 | 3508ms | 149,448 tok/s | MFU 29.8%
step 498/6184 | loss 3.5950 | bpb 1.1360 | lr 1.000 | 3507ms | 149,478 tok/s | MFU 29.8%
step 499/6184 | loss 3.5751 | bpb 1.1000 | lr 1.000 | 3508ms | 149,466 tok/s | MFU 29.8%
step 500/6184 | loss 3.5702 | bpb 1.1216 | lr 1.000 | 3505ms | 149,562 tok/s | MFU 29.9%
>> sample: <|endoftext|>- The study of the Great Awakening in the Great Awakening - The study of the Great Awakening in the Great Awakening An overview of the study of the Great Awakening - The study of the Great Awakening in the Great Awakening - The study of the Great Awakening in the Great Awakening - The study of the Greatstep 986/6184 | loss 3.3652 | bpb 1.0247 | lr 1.000 | 3503ms | 149,684 tok/s | MFU 29.9%
step 987/6184 | loss 3.3869 | bpb 1.0688 | lr 1.000 | 3505ms | 149,593 tok/s | MFU 29.9%
step 988/6184 | loss 3.3612 | bpb 1.0315 | lr 1.000 | 3503ms | 149,678 tok/s | MFU 29.9%
step 989/6184 | loss 3.3799 | bpb 1.0608 | lr 1.000 | 3502ms | 149,719 tok/s | MFU 29.9%
step 990/6184 | loss 3.3701 | bpb 1.0465 | lr 1.000 | 3502ms | 149,718 tok/s | MFU 29.9%
step 991/6184 | loss 3.3629 | bpb 1.1073 | lr 1.000 | 3505ms | 149,578 tok/s | MFU 29.9%
step 992/6184 | loss 3.3885 | bpb 1.0934 | lr 1.000 | 3499ms | 149,838 tok/s | MFU 29.9%
step 993/6184 | loss 3.3677 | bpb 1.0508 | lr 1.000 | 3493ms | 150,093 tok/s | MFU 30.0%
step 994/6184 | loss 3.3899 | bpb 1.0503 | lr 1.000 | 3490ms | 150,239 tok/s | MFU 30.0%
step 995/6184 | loss 3.3832 | bpb 1.0307 | lr 1.000 | 3491ms | 150,177 tok/s | MFU 30.0%
step 996/6184 | loss 3.3642 | bpb 1.0535 | lr 1.000 | 3488ms | 150,324 tok/s | MFU 30.0%
step 997/6184 | loss 3.3538 | bpb 1.0287 | lr 1.000 | 3489ms | 150,275 tok/s | MFU 30.0%
step 998/6184 | loss 3.3978 | bpb 1.0700 | lr 1.000 | 3490ms | 150,226 tok/s | MFU 30.0%
step 999/6184 | loss 3.3751 | bpb 1.0584 | lr 1.000 | 3488ms | 150,327 tok/s | MFU 30.0%
step 1000/6184 | loss 3.3593 | bpb 0.9976 | lr 1.000 | 3491ms | 150,202 tok/s | MFU 30.0%
>> val bpb 1.0551
>> sample: <|endoftext|>The study of the natural environment's response to climate change is the first attempt at exploring the potential of environmental change as a response to the global climate change. The study of the natural environment's response to climate change is one of the most important questions to be answered by Earth science practitioners. The study of the natural environment
>> saved checkpoint at step 1000 -> checkpoints/d12.pt
step 1487/6184 | loss 3.2938 | bpb 0.9987 | lr 1.000 | 3503ms | 149,668 tok/s | MFU 29.9%
step 1488/6184 | loss 3.2698 | bpb 1.0464 | lr 1.000 | 3502ms | 149,704 tok/s | MFU 29.9%
step 1489/6184 | loss 3.2671 | bpb 1.0203 | lr 1.000 | 3502ms | 149,709 tok/s | MFU 29.9%
step 1490/6184 | loss 3.2770 | bpb 1.0582 | lr 1.000 | 3503ms | 149,652 tok/s | MFU 29.9%
step 1491/6184 | loss 3.2754 | bpb 0.9966 | lr 1.000 | 3503ms | 149,668 tok/s | MFU 29.9%
step 1492/6184 | loss 3.2668 | bpb 1.0516 | lr 1.000 | 3504ms | 149,614 tok/s | MFU 29.9%
step 1493/6184 | loss 3.2773 | bpb 1.0605 | lr 1.000 | 3502ms | 149,716 tok/s | MFU 29.9%
step 1494/6184 | loss 3.2950 | bpb 1.0392 | lr 1.000 | 3502ms | 149,691 tok/s | MFU 29.9%
step 1495/6184 | loss 3.2619 | bpb 0.9845 | lr 1.000 | 3502ms | 149,691 tok/s | MFU 29.9%
step 1496/6184 | loss 3.2622 | bpb 1.0229 | lr 1.000 | 3503ms | 149,686 tok/s | MFU 29.9%
step 1497/6184 | loss 3.2663 | bpb 1.0718 | lr 1.000 | 3501ms | 149,757 tok/s | MFU 29.9%
step 1498/6184 | loss 3.2972 | bpb 1.0009 | lr 1.000 | 3500ms | 149,801 tok/s | MFU 29.9%
step 1499/6184 | loss 3.2808 | bpb 1.0536 | lr 1.000 | 3500ms | 149,792 tok/s | MFU 29.9%
step 1500/6184 | loss 3.2850 | bpb 0.9899 | lr 1.000 | 3500ms | 149,812 tok/s | MFU 29.9%
>> sample: <|endoftext|>Videos & videos Why this problem might be a problem with some parts of your body. - Injuries to the joints - Pregnancy and birth - A change in lifestyle - Physical injury How does my body develop? Your brain is composed of a layer of white matter. These white matterstep 1986/6184 | loss 3.2342 | bpb 1.0269 | lr 1.000 | 3502ms | 149,707 tok/s | MFU 29.9%
step 1987/6184 | loss 3.1972 | bpb 0.9660 | lr 1.000 | 3504ms | 149,647 tok/s | MFU 29.9%
step 1988/6184 | loss 3.2262 | bpb 1.0617 | lr 1.000 | 3505ms | 149,586 tok/s | MFU 29.9%
step 1989/6184 | loss 3.2300 | bpb 0.9829 | lr 1.000 | 3505ms | 149,596 tok/s | MFU 29.9%
step 1990/6184 | loss 3.2074 | bpb 1.0365 | lr 1.000 | 3504ms | 149,620 tok/s | MFU 29.9%
step 1991/6184 | loss 3.2127 | bpb 1.0154 | lr 1.000 | 3500ms | 149,803 tok/s | MFU 29.9%
step 1992/6184 | loss 3.2274 | bpb 0.9487 | lr 1.000 | 3499ms | 149,829 tok/s | MFU 29.9%
step 1993/6184 | loss 3.2223 | bpb 0.9896 | lr 1.000 | 3502ms | 149,720 tok/s | MFU 29.9%
step 1994/6184 | loss 3.2132 | bpb 0.9446 | lr 1.000 | 3503ms | 149,667 tok/s | MFU 29.9%
step 1995/6184 | loss 3.2187 | bpb 0.9899 | lr 1.000 | 3525ms | 148,738 tok/s | MFU 29.7%
step 1996/6184 | loss 3.2127 | bpb 0.9932 | lr 1.000 | 3549ms | 147,743 tok/s | MFU 29.5%
step 1997/6184 | loss 3.1791 | bpb 0.9453 | lr 1.000 | 3563ms | 147,157 tok/s | MFU 29.4%
step 1998/6184 | loss 3.2242 | bpb 1.0276 | lr 1.000 | 3563ms | 147,149 tok/s | MFU 29.4%
step 1999/6184 | loss 3.2165 | bpb 0.9426 | lr 1.000 | 3564ms | 147,106 tok/s | MFU 29.4%
step 2000/6184 | loss 3.2317 | bpb 0.9720 | lr 1.000 | 3552ms | 147,588 tok/s | MFU 29.5%
>> val bpb 1.0177
>> sample: <|endoftext|>The history of the - military may be divided into three periods: war, war-oriented and war of attrition. The - military is a new type of force with the purpose of strengthening -’s military presence in the West and spreading the message of peace and security, and of bringing the - military to a new
>> saved checkpoint at step 2000 -> checkpoints/d12.pt
step 2487/6184 | loss 3.1387 | bpb 0.9388 | lr 1.000 | 3520ms | 148,946 tok/s | MFU 29.7%
step 2488/6184 | loss 3.1586 | bpb 1.0009 | lr 1.000 | 3505ms | 149,593 tok/s | MFU 29.9%
step 2489/6184 | loss 3.1931 | bpb 1.0120 | lr 1.000 | 3501ms | 149,759 tok/s | MFU 29.9%
step 2490/6184 | loss 3.2069 | bpb 0.9483 | lr 1.000 | 3504ms | 149,634 tok/s | MFU 29.9%
step 2491/6184 | loss 3.2065 | bpb 0.9902 | lr 1.000 | 3506ms | 149,554 tok/s | MFU 29.9%
step 2492/6184 | loss 3.1798 | bpb 0.9296 | lr 1.000 | 3511ms | 149,329 tok/s | MFU 29.8%
step 2493/6184 | loss 3.1730 | bpb 0.9887 | lr 1.000 | 3510ms | 149,372 tok/s | MFU 29.8%
step 2494/6184 | loss 3.1976 | bpb 1.0165 | lr 1.000 | 3503ms | 149,650 tok/s | MFU 29.9%
step 2495/6184 | loss 3.1854 | bpb 0.9901 | lr 1.000 | 3513ms | 149,261 tok/s | MFU 29.8%
step 2496/6184 | loss 3.1764 | bpb 0.9885 | lr 1.000 | 3503ms | 149,656 tok/s | MFU 29.9%
step 2497/6184 | loss 3.1806 | bpb 0.9894 | lr 1.000 | 3489ms | 150,266 tok/s | MFU 30.0%
step 2498/6184 | loss 3.1626 | bpb 1.0217 | lr 1.000 | 3481ms | 150,598 tok/s | MFU 30.1%
step 2499/6184 | loss 3.1928 | bpb 0.9699 | lr 1.000 | 3482ms | 150,555 tok/s | MFU 30.1%
step 2500/6184 | loss 3.1646 | bpb 0.9211 | lr 1.000 | 3478ms | 150,726 tok/s | MFU 30.1%
>> sample: <|endoftext|>|This page is part of:| |This guide is also available in: English| |This article needs additional citations for verification. (February 2013)| |The name of a person or company of the United States; a branch of foreign business.| |This section needs additional citations for verification.
>> saved checkpoint at step 2500 -> checkpoints/d12.pt